
大数据相关知识

大数据相关知识
青夢大数据相关知识
Hadoop大数据生态体系
一、核心问题:海量数据处理挑战
- 传统数据库瓶颈
MySQL等关系型数据库在TB/PB级数据场景下存在性能瓶颈(存储、计算、并发) - 大数据核心特征
Volume(规模大)、Velocity(增长快)、Variety(类型多) - 解决思路
分治策略:存储切分 + 分布式计算
二、Hadoop核心组件
Hadoop = HDFS + MapReduce + YARN
1. HDFS (Hadoop Distributed File System)
- 核心作用:分布式存储
- 核心机制:
- 文件切分为固定大小 Block(默认128MB)
- 数据冗余存储(默认3副本)
- 角色:
DataNode:实际存储数据块的节点NameNode:管理文件系统元数据(文件-block映射)
2. MapReduce
- 核心作用:分布式计算框架
- 计算模型:
graph LR A[Input Splits] --> B(Map Tasks) B --> C[Shuffle & Sort] C --> D(Reduce Tasks) D --> E[Final Output]
- 编程接口:
map():处理分片数据(键值对转换)reduce():聚合map结果
3. YARN (Yet Another Resource Negotiator)
核心作用:集群资源管理与调度
核心概念:
- Container:资源抽象单元(CPU+内存隔离的JVM进程)
- ResourceManager:全局资源调度器
- NodeManager:节点资源监控
与Docker/K8s区别:
- YARN Container ≠ Docker Container(资源隔离机制不同)
- YARN仅管理计算资源,不提供环境隔离
维度 YARN Docker/Kubernetes 核心定位 大数据计算资源调度 容器化应用编排平台 资源模型 基于JVM的进程级资源隔离 OS级容器虚拟化(cgroups/namespace) 调度单位 Application(含多个Container) Pod(含多个容器) 调度目标 计算任务(MapReduce/Spark等) 长期运行的服务(Deployment/StatefulSet) 资源申请方式 动态协商(ResourceRequest) 静态声明(Resource Limits/Requests) 失败处理 任务重试(Task Attempts) 容器重启/Pod重建 存储管理 依赖HDFS 原生Volume/PV/PVC体系 网络模型 无专用网络层 CNI插件(Service/Ingress) 典型工作负载 批处理/分析任务 微服务/Web应用/DB 生态扩展 Hadoop生态计算框架 Helm/Operator/CRD 本质区别:
graph LR A[资源管理目标] --> B(YARN:计算任务调度) A --> C(K8s:应用服务编排) D[隔离机制] --> E(YARN:进程级资源限制) D --> F(Docker:内核级虚拟化) G[生命周期] --> H(YARN:分钟级短任务) G --> I(K8s:长期运行服务)
graph TD Y[YARN架构] --> RM[ResourceManager] RM --> NM1[NodeManager] RM --> NM2[NodeManager] NM1 --> C1[Container] NM1 --> C2[Container] NM2 --> C3[Container] K[Kubernetes架构] --> CM[Control Plane] CM --> W1[Worker Node] CM --> W2[Worker Node] W1 --> P1[Pod] W1 --> P2[Pod] P1 --> D1[Container] P1 --> S1[Sidecar]
三、生态工具演进
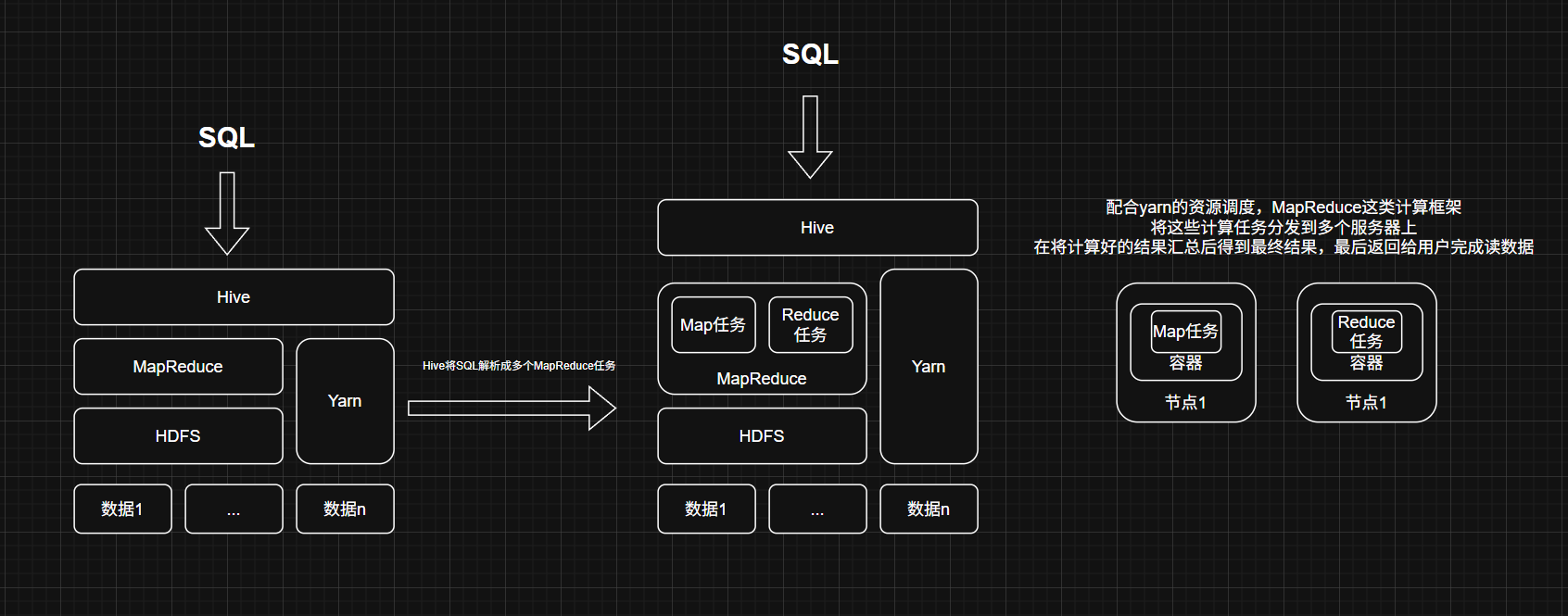
1. Hive
- 定位:SQL-on-Hadoop工具
- 核心价值:
- 将SQL查询转换为MapReduce任务
- 降低大数据分析门槛
- 架构:
graph LR SQL[用户SQL] --> Hive Hive -->|解析优化| MR[MapReduce Job] MR --> YARN
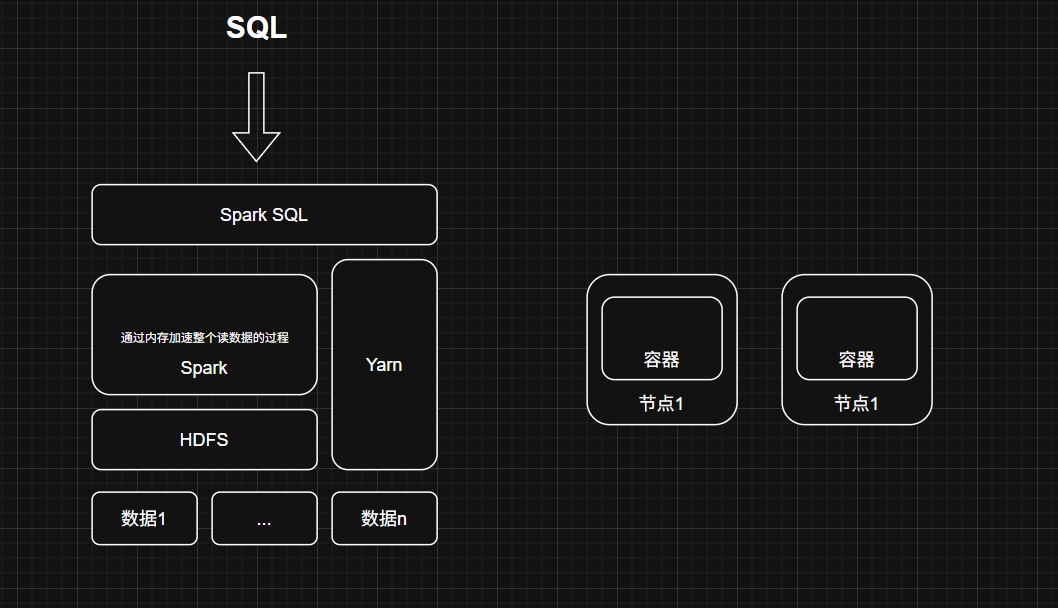
2. Spark
- 定位:内存优化计算引擎
- 核心改进:
- DAG执行引擎(替代MapReduce)
- 中间结果优先存内存
- 生态组件:
- Spark SQL:替代Hive SQL的高性能查询
- Spark Streaming:微批流处理
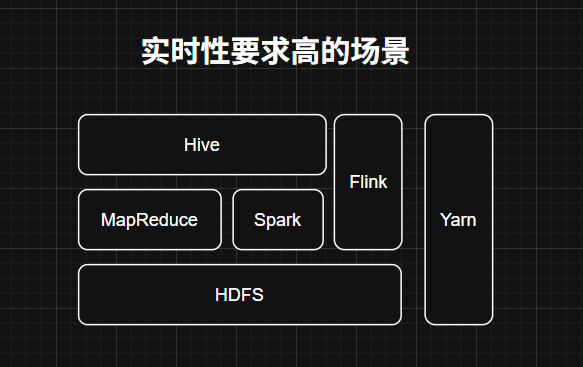
3. Flink
- 定位:实时流处理引擎
- 核心特性:
- 真正的逐事件处理(非微批)
- 毫秒级延迟
- 适用场景:实时风控、监控告警
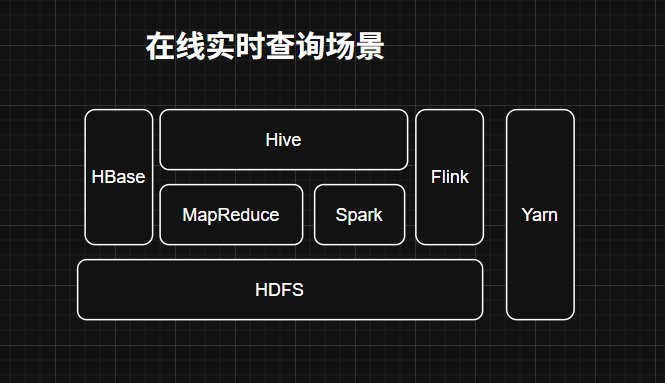
4. HBase
- 定位:分布式NoSQL数据库
- 核心价值:
- 支持PB级数据毫秒级读写
- 基于HDFS的LSM树存储引擎
- 适用场景:实时查询、高并发访问
四、典型数据处理流程
离线分析场景
graph LR
A[数据写入] --> B[HDFS]
B --> C[Hive SQL]
C --> D{执行引擎}
D -->|历史数据| E[MapReduce]
D -->|性能优先| F[Spark]
F --> G[YARN调度]
G --> H[计算结果]
实时处理场景
graph LR A[数据流] --> B[Flink] B --> C[实时计算结果] D[业务系统] --> E[HBase] E --> F[毫秒级查询]
评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果







